Visualizing AI: Understanding Embeddings with Heatmaps
In the fascinating world of artificial intelligence (AI), word embeddings are a fundamental concept that enables machines to understand human language. In this article, we’ll dive into what word embeddings are, why they are crucial for AI, and demonstrate their power through a practical example with code provided on GitHub. We’ll visualize the relationships between different words using a heatmap, making the abstract concept of embeddings more tangible and insightful.

What Are Embeddings?
Embeddings are numerical representations of words in a continuous vector space. They capture semantic relationships between words, enabling AI systems to understand context and meaning. In a well-trained embedding space, similar words are located near each other, while dissimilar words are far apart.
Why Are Embeddings Important?
- Semantic Understanding: Word embeddings allow AI models to grasp the meaning and context of words, which is essential for tasks like translation, sentiment analysis, and information retrieval.
- Dimensionality Reduction: By converting words into vectors, embeddings reduce the complexity of language data, making it more manageable for machine learning algorithms.
- Transfer Learning: Pre-trained embeddings can be used across various NLP tasks, providing a robust foundation and reducing the need for extensive training data.
Getting an Embedding for a Word
To understand embeddings better, let’s see how we can obtain the embedding for a single word. Here’s a simple code snippet using the OpenAI library:
from langchain_openai import OpenAIEmbeddings
# Get embedding for a word.
embedding_function = OpenAIEmbeddings()
vector = embedding_function.embed_query("apple")
print(f"Vector for 'apple': {vector}")
print(f"Vector length: {len(vector)}")This code retrieves the vector representation of the word “apple.” The vector is a list of numbers representing the word’s meaning and context in a way AI can understand.

Here’s what this means:
- Vector: The array of numbers represents the word “apple” in a high-dimensional space. Each number (or dimension) captures a different aspect of the word’s meaning and context.
- Vector Length (1536): This indicates the number of dimensions in the embedding space. A higher number of dimensions allows for more nuanced and detailed representations of words. In this case, the word “apple” is represented in a 1536-dimensional space.
Comparing Word Embeddings
Next, we’ll compare the embeddings of different words to understand their relationships. We define a function to compare the similarity between two words. This function uses a pairwise embedding distance evaluator to compute a similarity score.
from langchain_openai import OpenAIEmbeddings
from langchain.evaluation import load_evaluator
def compare_embeddings(word1, word2):
evaluator = load_evaluator("pairwise_embedding_distance")
x = evaluator.evaluate_string_pairs(prediction=word1, prediction_b=word2)
print(f"Comparing {word1} and {word2}: {x['score']}")
return x['score']This function calculates the similarity score between two words, providing insight into how closely related they are within the embedding space.
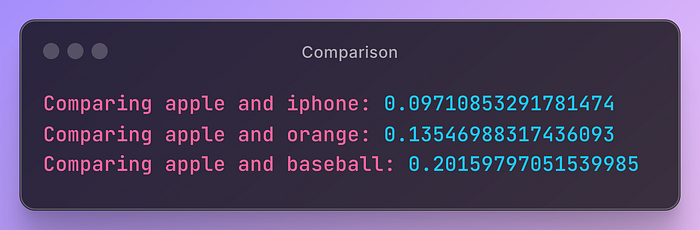
Understanding the Similarity Score
- Similarity Score: Indicates how similar the embeddings of the words are. A lower score means greater similarity. In this case, apple and iPhone have a moderate similarity score suggesting they are related but not identical. Apple and orange have a higher score indicating a closer relationship as both are fruits. Apple and baseball have the highest scores, showing they are quite different in context.
Visualizing Embeddings with Heatmaps
To make the concept of embeddings clearer, we’ll use a Python script to compare different words and visualize their relationships with a heatmap. This approach allows us to see how words are related in the embedding space.
Generating the Heatmap
Now, we compare a list of words, store their similarity scores, and create a heatmap to visualize these relationships.
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
if __name__ == "__main__":
words_list = ["apple", "iphone", "orange", "windows", "microsoft", "bat",
"baseball", "animal", "mouse", "computer"]
# Create a 2D array to store the similarity scores
scores = []
for word in words_list:
row = []
for word2 in words_list:
row.append(compare_embeddings(word, word2))
scores.append(row)
# Create heatmap
data = np.array(scores)
fig, ax = plt.subplots(figsize=(10, 10))
sns.heatmap(data, xticklabels=words_list, yticklabels=words_list, annot=True, fmt=".2f", cmap='RdYlGn_r', ax=ax)
plt.title("Word Embedding Similarity Heatmap")
plt.savefig('heatmap.png')
plt.show()In this section, we create a list of words and compute their pairwise similarity scores, storing them in a 2D array. This data is then visualized as a heatmap using seaborn.
Insights from the Heatmap
The heatmap visually represents the similarity scores between the selected words. Here are some key observations:
- Clusters of Similar Words: Words like “apple” and “iphone” or “microsoft” and “windows” are close to each other, indicating high similarity.
- Semantic Distances: Words from different domains, such as “animal” and “computer,” show lower similarity scores, highlighting their semantic distance.
Conclusion
Word embeddings are a fundamental component of AI, enabling machines to understand and process human language effectively. Through the visualization of word embeddings with a heatmap, we gain valuable insights into the semantic relationships between words. This exploration not only enhances our understanding of AI but also demonstrates the power of embeddings in capturing the nuances of language.
You can find the script in the GitHub repository, you can experiment with different words and embeddings. Happy coding!

